生産性インフュージョン向けCUDAプロファイラー
 CUDAプロファイルの新しい
CUDAプロファイルの新しい本稿では、生産性インフュージョンの難しさと、CUDAプロファイラーがどのように異なるかを説明します。
Graphsignalは、低オーバーヘッドで常時稼働するプロファイラーであり、root権限不要で、インフュージョンエンジンレベルの知見を提供します。
AIモデルの推論を本番環境で効率的に実行するためのプロファイリングツールとして、Graphsignalが注目されています。この記事では、従来の開発用プロファイラーでは対応できない本番環境での推論プロファイリングの課題と、Graphsignalがどのようにそれを解決しているかを解説します。
本番環境での推論プロファイリングの特徴
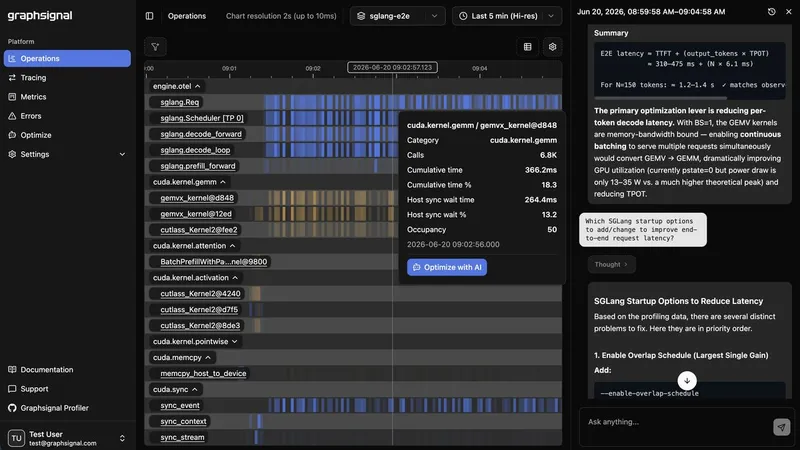
従来のCUDAプロファイラーは、ワークステーションで単一の実行を監視する開発者向けに設計されていました。一方、本番環境では数千のリクエストが同時に処理され、GPUがフル稼働しています。このため、通常のプロファイリングでは捕捉できない現象が発生するため、特別な設計が必要です。
プロファイリングの課題と解決策
すべてのカーネル呼び出しを記録すると、トレースファイルが膨大になり、生産環境では処理が困難です。また、2段階のメトリクスでは重要な情報が隠れてしまいます。その間のバランスを取るため、GPU活動の詳細な時間軸を維持しつつ、個別呼び出しを追跡しない設計が求められます。
Graphsignalの特徴と競合との違い
Graphsignalは、CUDA活動記録からカーネルタイムラインを生成し、推論エンジンの概念に属性を付けています。これにより、GPU時間の分類や、長尾の集約が可能になります。また、eBPFプロファイラーとの違いとして、ホスト側の同期情報やエンジンメトリクスの統合も特徴です。
まとめ
Graphsignalは、本番環境でのAI推論プロファイリングに特化したツールとして、従来のプロファイラーでは対応できない課題を解決しています。今後、AIモデルの運用効率向上に貢献する可能性があります。
原文の冒頭を表示(英語・3段落のみ)
Most CUDA profilers were built for a developer staring at a single run on a workstation. Production inference is a different problem: thousands of requests in flight, GPUs running flat out, and behavior that only shows up under real load. This post looks at what makes profiling production inference hard, and what a profiler designed for it does differently.
What Makes Production Inference Profiling Different
Full kernel traces don’t scale. A serving engine launches kernels at enormous rates. Recording every single kernel call - the default mental model for a dev profiler - produces traces too large to store, move, or reason about, and adds overhead you can’t afford in production. At the same time, second-level metrics hide everything that matters. The useful target is in between: a timeline resolution high enough to expose where GPU activity actually goes, without tracing every call individually.
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。